


#003 AB Testing es mucho más

Hoy toca CRO.
CRO es una de las disciplinas más completas del ámbito digital y una de sus técnicas más conocidas es AB Testing. Esta esconde toda una serie de laberintos que van más allá de Google Optimize o VWO. En la 3ª edición de Leanalytics aprenderás que:
‘AB Testing es mucho más’
Antes, algo de contexto:
Un AB test se inicia con una hipótesis. En futuras ediciones de Leanalytics profundizaré más en cómo (y sobre todo por qué) formular hipótesis para experimentación en negocios digitales, pero por el momento nos quedaremos en la superficie:
Un ejemplo de hipótesis: “Para los usuarios no-registrados en desktop, si dotamos de mayor relevancia visual al botón ‘tramitar pedido’, se producirá una identificación clara por parte del usuario porque actualmente el botón no es visible, lo que generará un incremento de accesos a checkout”
La hipótesis no tiene por qué ser verdadera. Es solo el primer paso para experimentar en nuestro producto digital, definir los outputs esperados y nos sirve para hacer ‘buena experimentación’ y no el típico ‘probemos cosas, a ver qué pasa’.
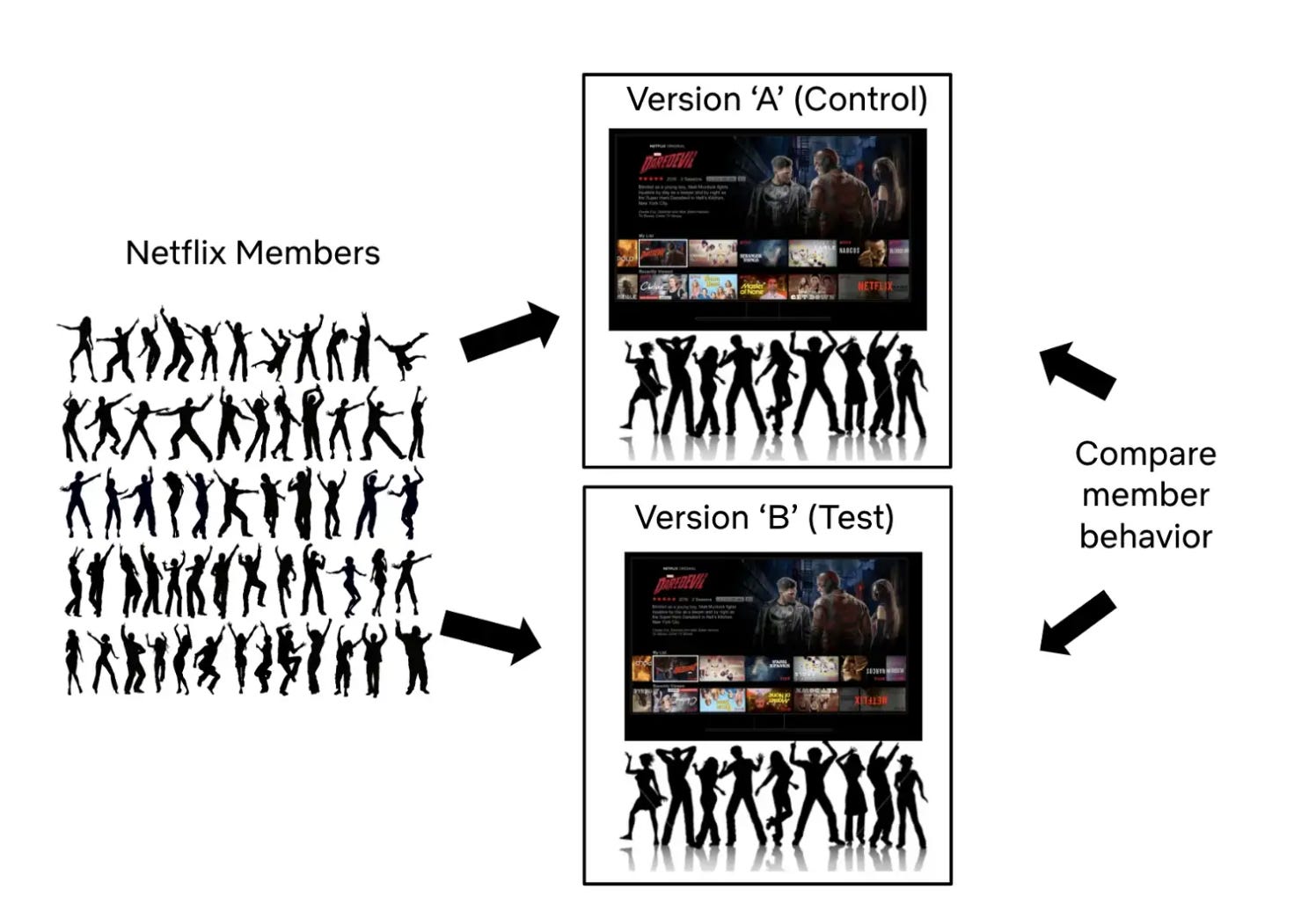
¿Qué es un test AB y cómo se interpreta?
Es un tipo de experimento en el que se generan dos grupos y se aplica un tratamiento, modificación o estímulo a solo uno de ellos. Así, se puede evaluar si se genera (o no) un impacto positivo o negativo con esa modificación y qué opción resulta mejor.
Siguiendo el ejemplo de la hipótesis anterior, esa modificación podría ser que el botón sea más grande, de un color diferente, de otra forma o que esté ubicado en otro punto de la interfaz, entre otros.
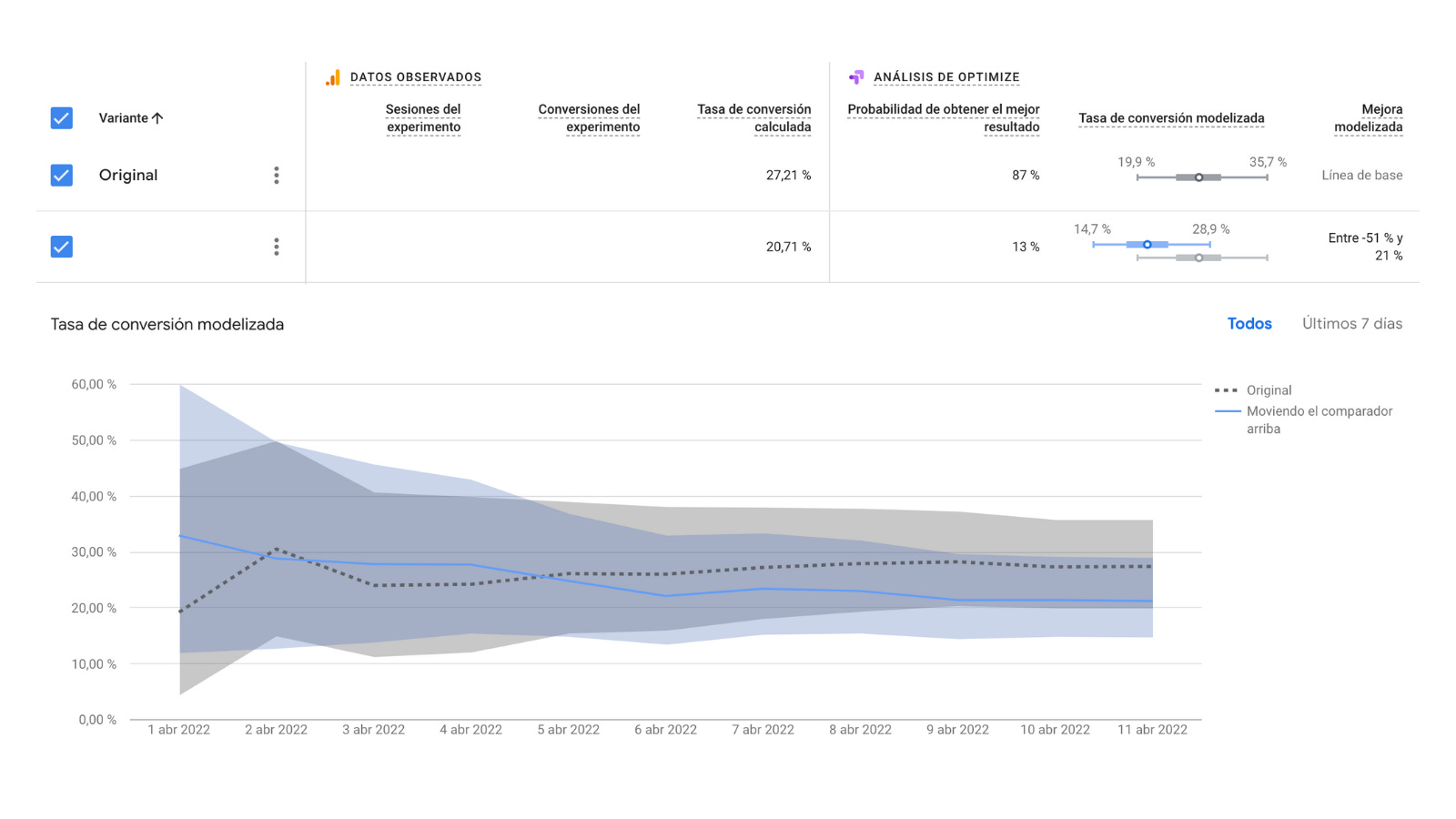
Como se puede ver en esta tabla de Google Optimize con resultados, la variante original (también llamada grupo de control) genera una tasa de conversión de casi 7 puntos por encima de la 2ª variante (también llamada grupo experimental).
¿Fácil, verdad? Pues no es (solo) así. No es tan simple generar conocimiento con AB Testing.

La importancia de la estadística
Observa la métrica ‘Sesiones del experimento’. La variante original solamente ha sido generada en 136 sesiones y la variante B en 140. Esto suele suceder cuando estamos ejecutando un experimento en una página con muy pocas visitas o porque el experimento se ha ejecutado durante muy poco tiempo.
Para considerar que un experimento es estadísticamente significativo, debe ejecutarse ante una muestra representativa de la población. Si experimentamos sobre una muestra muy reducida, no podremos inferir si los resultados son extrapolables a toda la población.
La estadística inferencial consiste en un conjunto de técnicas que permite el estudio de muestras (en este caso los usuarios de la variante A y los usuarios de la variante B) para así inferir (a través de la inducción) comportamientos atribuibles a toda la población.
Introducción a la Probabilidad

La relación entre las muestras y la población en ocasiones se definen en términos de probabilidad. Imagina que debes seleccionar una canica de un bote que contiene 50 canicas negras y 50 blancas (En este ejemplo, el bote de canicas es la población y la única canica que se seleccionará es la muestra).
Aunque no se puede garantizar el resultado exacto de tu muestra, es posible hablar sobre los posibles resultados en términos de probabilidad. En este caso, tienes una probabilidad del 50% de obtener cualquier color.
Ahora considera otro bote (población) que tiene 90 canicas negras y solo 10 blancas. No puedes especificar el resultado exacto de una canica (la muestra), pero ahora sabes que la muestra probablemente será una canica negra. Al conocer la composición de una población, podemos determinar la probabilidad de obtener muestras específicas.
Introducción a Inferencia

La estadística inferencial (en el marco limitado de este post) inicia con una muestra para luego responder una pregunta que se traslada a la población. Por ejemplo, ¿Qué tan probable es que te cases con alguien cuyo apellido comience con la misma letra que tu apellido? Esto puede sonar como una pregunta tonta, pero fue objeto de un estudio de investigación que examinó los factores que contribuyen a la atracción interpersonal.
Volvamos de nuevo a las canicas (Pero esta vez, el bote núm. 1 contiene 50 canicas negras y 50 blancas y el bote núm. 2 contiene 90 canicas negras y solo 10 blancas). Supón que tienes los ojos vendados cuando seleccionas la muestra (la canica), por lo que no sabes de qué población (bote) proviene. Tu tarea es observar la muestra que obtienes y luego decidir qué bote es el más probable.
Con una única muestra (una única canica) no podrías saber de qué bote sale. Pero si seleccionas una muestra de n = 4 canicas y todas son negras, ¿qué bote elegirías? Sería relativamente improbable obtener esta muestra del bote 1 ya que es casi seguro que obtendrás al menos 1 canica blanca. Por otro lado, esta muestra tendría una alta probabilidad de provenir del bote 2, donde casi todas las canicas son negras.
Es decir, ahora estás usando la muestra para hacer una inferencia sobre la población
Test AB & Engagement Bias
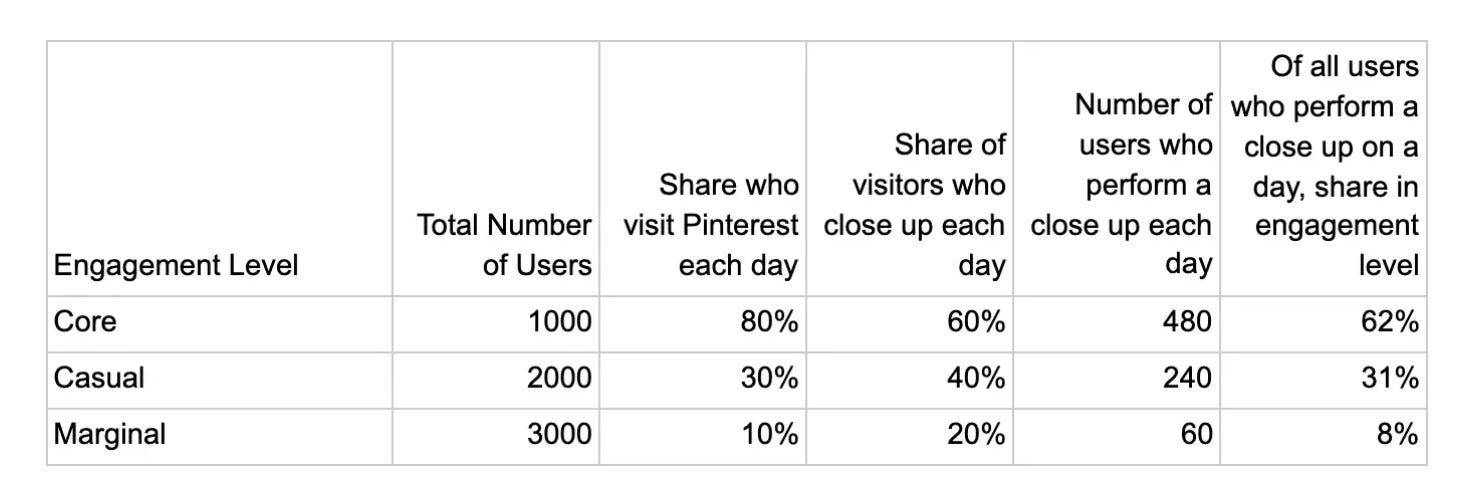
Existen sesgos y problemas también en la toma de la muesta, la interpretación de los datos e incluso luego cuando lanzas a producción. No podemos olvidar que los experimentos son el paso previo a un lanzamiento a la web/app real (aunque Google Optimize permite actualmente ‘segmentar’ a un 100% de los usuarios…).
Uno problema típico y muy peliagudo es Engagement Bias: Imagina que ejecutas un test AB, esperas hasta tener un intervalo de confianza interesante y tu variante experimental genera un +10% en tu métrica objetivo con respecto al grupo de control
No hay impedimentos para lanzar la nueva feature pero, por si acaso le echas un vistazo y, no entiendes por qué, pero esa variante B que tan buen resultado te dio en el test AB no parece generar en el mundo real tanto como generó en el experimento.
'Engagement Bias' sucede cuando no generas el mismo efecto en los 'unengaged users' que en los 'engaged users'. Es decir, en el marco de un producto digital, confiaste en los resultados a corto plazo (la de aquellos usuarios que entran a menudo a tu sitio web), lanzaste a producción y ya después viste cómo aquellos usuarios que todavía están en fases de descubrimiento e investigación no reaccionan a ese mismo estímulo del mismo modo.
Alargar el tiempo de ejecución de los experimentos es un buen método para aliviar este sesgo, así como segmentar el experimento en función del grado de engagement del usuario y evaluar diferencias sustanciales entre usuarios fieles y casuales. Es decir, tiempo y calidad de la muestra importan.
Esto explica algunos fenómenos que suceden cuando aplicamos test AB y observamos distintos resultados en distintos momentos del tiempo. Habitualmente, se atribuye a estacionalidad de consumo, pero habitualmente (con un margen +- aceptable) se debe a que la muestra no es estadísticamente significativa.

AB Testing es mucho más
Es algo más que ver un +5% en la variante B y tomar una decisión. Una decisión que muy probablemente no podrán ser extrapolables a la realidad del negocio si no se tienen en cuenta principios mínimos es estadística.
Conocer heurísticos de diseño, aprender el sistema 1 y 2 de Kahneman y su obra alrededor de Behavioural Economics, entender cómo funciona la analítica de datos y saber de negocio digital es importante, pero la introducción de la estadística en CRO es innegociable.
En siguientes ediciones profundizaré con más conceptos de estadística relevantes en experimentación y CRO como p-value, sample size, permutation test o los tipos de hipótesis que pueden intervenir en un test AB.
No statistics, no party
Fuentes de la 3ª edición:
Peter Bruce, Andrew Brucce & Peter Gedeck - Practical Statistics for data scientists
Frederik Graveter, Larry B Walnau - Statistics for the behavioural economics
Ricardo Tayar - CRO Profesional (estrategia y práctica)
Pinterest Engineering - Artículo sobre Engagement Bias
Estudio - Investigación apellidos