
#004 Datos y toma de decisiones en CRO (Parte 1)
#004 Datos y toma de decisiones en CRO (Parte 1)
Tomar decisiones basadas en datos es fácil, lo que es difícil es tomar buenas decisiones basadas con datos.

Data-driven decision making
El concepto estrella de los últimos 15 años. Ninguna conferencia tech sin él. Tomar decisiones basadas en datos es inherente a la experimentación, por ello, en esta 4ª edición de Leanalytics (que como me quedó un poco larga la he dividido en partes) hablaremos de:
‘Datos y toma de decisiones en CRO’
En la pasada edición de Leanalytics hablamos de cómo la estadística tiene un papel fundamental en técnicas de experimentación. En esta edición (y las siguientes) profundizaremos un poco más y trataremos el escabroso tema de los falsos positivos, los falsos negativos y los errores típicos que podemos cometer cuando experimentamos.
Falsos positivos
Imagina que ejecutas un test AB y los resultados de la variante son holgadamente superiores. Esperas un poco y llegas a la conclusión de que la opción B es la correcta. Lo tienes todo atado y bien atado, pero ¿es posible que sea un falso positivo?
En un test AB, un falso positivo (Type I error) sucede cuando los datos del experimento indican una diferencia significativa entre grupo de control (A) y variante (B), pero en realidad no hay tal diferencia.
Los falsos positivos pueden acabar con tu proyecto. Imagina que encuentras una oportunidad, convences a tu organización de que ese es el camino correcto y que se debe invertir en ella. Tienes los datos y estos te amparan.
La organización empieza a movilizar recursos y nada mueve la aguja. Se quema más dinero. Se invierte en más recursos humanos y técnicos y nada. ¿Por qué? La respuesta es evidente: Viste un espejismo. No fueron sesgos. Fueron los datos. Fue un falso positivo.
Falsos negativos
Existe la otra cara de la moneda en el asunto del falso positivo y es el falso negativo.
En un test AB, un falso negativo (Type II error) sucede cuando los datos del experimento no indican una diferencia significativa entre grupo de control (A) y variante (B), cuando en realidad sí hay tal diferencia.
En este caso, imagina que ejecutas un test AB y los resultados de la variante son definitivamente peores que el grupo de control, cuando, realmente esa variante generaría mucho mejor rendimiento que el grupo de control.
Los falsos negativos significan la pérdida de una oportunidad. En este caso, los datos concluyen que no existe ese sendero en el que la organización podría invertir y lograr amplio rendimiento. Como sucede con los falsos positivos, fueron los datos los que dictaminaron sentencia.
Y como dice Al Gore, aquí viene una verdad incómoda:
No podemos hacer que los falsos positivos y los falsos negativos desaparezcan al 100%. De hecho, se intercambian entre sí. Diseñar experimentos para que la tasa de falsos positivos sea reducida aumenta la tasa de falsos negativos.
Falsos positivos & significancia estadística
Aceptados estos dos incómodos compañeros de viaje (en futuras ediciones de Leanalytics se profundizará en cómo lidiar con esto, pero para los lectores más impacientes, dejo este enlace), podemos llegar a la cuestión de “qué ratio de falsos positivos estoy dispuesto a tolerar”.
Por convención, la tasa de falsos positivos suele estar en un 5%. Imagina que trabajamos con una herramienta de detección de gatitos y perritos a través de imágenes. De cada 100 imágenes, cometeríamos un error 5 veces. Diríamos que una imagen contiene una gatito cuando realmente no es un gatito en un 5% de ocasiones.

Esta tasa tiene una estrecha relación con la significación estadística y p-valor, pero para profundizar en ello, usaremos el azar. Imagina que quiero saber si esta moneda está trucada o no, es decir si cae más veces por el lado de la cara que por el lado de águila, es decir, que la probabilidad no es del 50% para ambos lados.

Para decidir si está trucada o no, lanzaremos la moneda 100 veces y calcularemos el porcentaje de resultados de cada lado. Ya sea por aleatoriedad, el viento o porque somos un poco torpes, no esperamos exactamente 50 caras y 50 cruces, pero ¿cuánta desviación de 50 es demasiado? ¿Cuándo consideramos que tenemos pruebas suficientes para rechazar la afirmación de que la moneda es, realmente, justa?
¿Estarías dispuesto a concluir que la moneda es injusta si 60 de cada 100 lanzamientos fueran cara? ¿o mejor 70? Definitivamente, necesitamos un método para trabajar con la tasa de falsos positivos.
Primero, supondremos que la moneda no está trucada (esta sería nuestra hipótesis nula) y buscaremos pruebas convincentes contra esta hipótesis nula a partir de los datos. Para constituir una evidencia convincente, calculamos la probabilidad de cada resultado posible asumiendo que la hipótesis nula es verdadera.
Es decir, calculamos la probabilidad de que 100 lanzamientos produzcan una cara, dos caras, tres caras y así sucesivamente hasta 100 caras (suponiendo que la hipótesis nula es verdadera, es decir, que la moneda no está trucada).
Cada uno de estos posibles resultados y sus probabilidades asociadas pueden visualizarse en la siguiente gráfica y tendría una estructura tal que así, como una distribución normal:
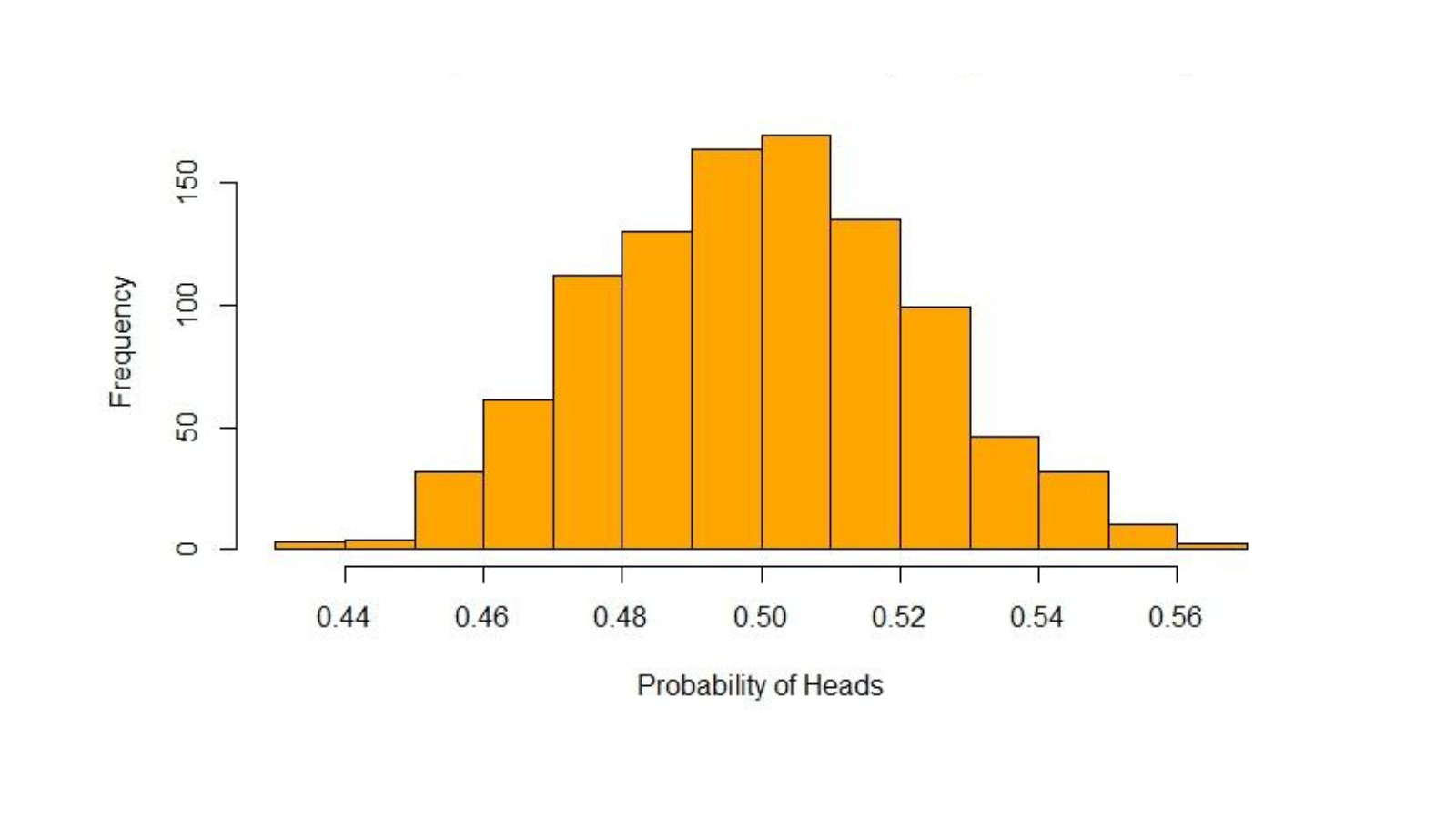
Una vez realizado esto, podemos comparar esta distribución (calculada bajo la premisa de que la moneda no está trucada) con los datos recopilados del experimento. Si observamos que el 55% de lanzamientos en el experimento dan cara y queremos cuantificar si esta observación es evidencia convincente de que la moneda sí está trucada contaremos las probabilidades asociadas con cada resultado que es menos probable que nuestra observación.
“La posibilidad de ver un resultado tan extremo como nuestra observación si la hipótesis nula fuera cierta” es el p-valor. Básicamente, p-valor nos ayuda a diferenciar resultados que son producto del azar, de resultados que son estadísticamente significativos. Es decir, nos ayuda a lidiar con los falsos positivos.
En nuestro caso, la hipótesis nula es que la moneda no está trucada, la observación es un 55% de caras tras realizar 100 lanzamientos y el p-valor es de 0,32. Esto se interpretaría así: Si repitiéramos muchas veces el experimento de lanzar una moneda 100 veces y calculáramos el ratio de caras con una moneda no trucada (hipótesis nula cierta), en el 32% de esos experimentos el resultado mostraría al menos 55 caras o 55 cruces.
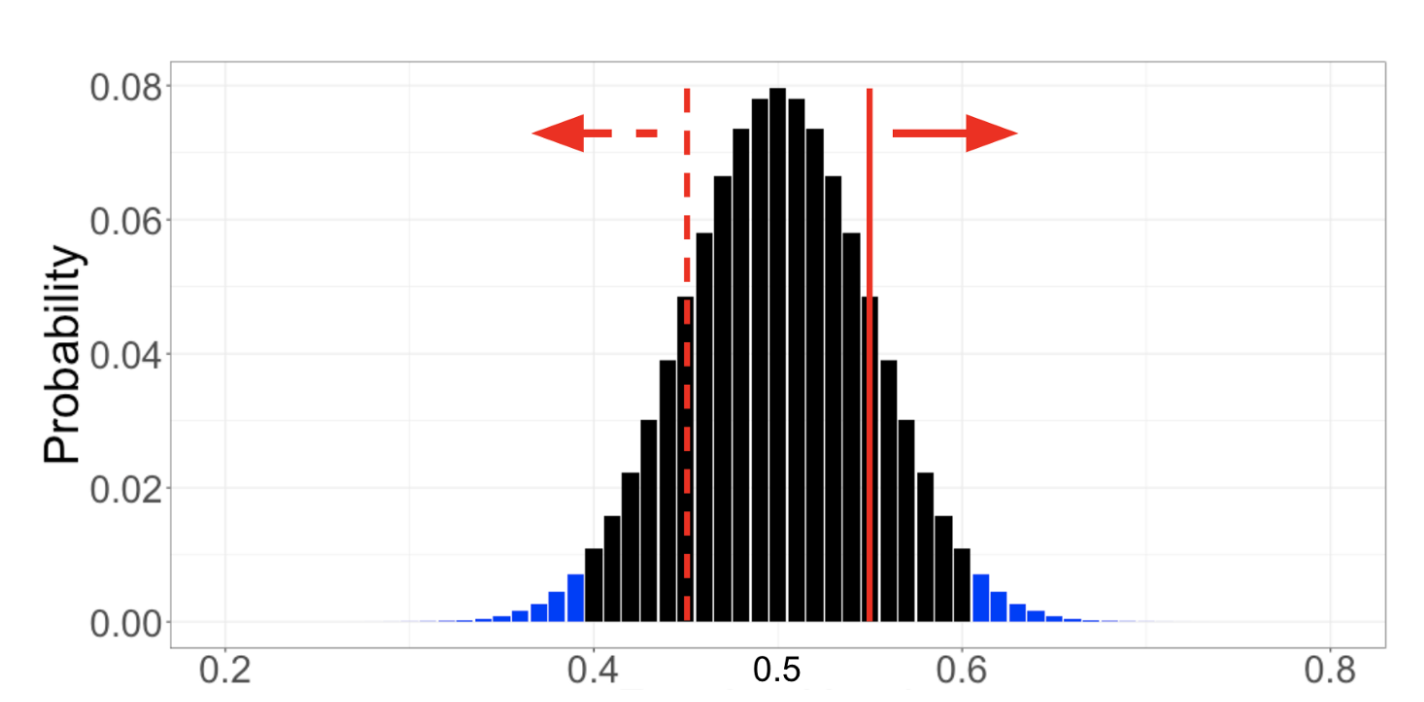
P-valor en un test AB
¿Cómo usamos P-valor para decidir si hay evidencia estadísticamente significativa de que la moneda está trucada o que nuestra variante está generando mejoras? Como se ha dicho anteriormente, la convención dice que hay un efecto estadísticamente significativo si el p-valor es inferior a 0,05.
En el caso de la moneda, se calcula un p-valor de 0,32. Debido a que el p-valor es mayor que el nivel de significancia de 0,05, se puede concluir que no hay evidencia estadísticamente significativa que la moneda esté trucada.
Llevado al caso de un Test AB, existen dos opciones:
Mi variante genera un cambio en el comportamiento de los usuarios (p-valor < 0,05)
No hay evidencia estadísticamente significativa de que la variante genere un cambio en el comportamiento de los usuarios (p-valor > 0,05)
Si tenemos en cuenta p-valor a la hora de evaluar los resultados de los experimentos, la probabilidad de tomar mejore decisiones aumentará.
Experimentar, leer datos y tomar decisioness
Los datos no mienten, pero podemos inferir comportamientos que no son reales ni representativos.
Puedes ver cómo tu variante es superior al grupo de control. Puedes esperar un tiempo más que prudencial a obtener una gran y significactiva muestra, pero no puedes ser inmune a los falsos positivos durante la experimentación en negocios digitales.
Los falsos positivos pueden acabar contigo y tu proyecto si no creas barreras y un método de trabajo que incluye la estadística. Reducir su impacto y tomar conciencia de que existen los falsos positivos es el primer paso para tomar buenas decisiones.
Tomar decisiones basadas en datos ha sido el gran leitmotiv de estos últimos 15 años a raíz del auge digital. Creer que aquello que nos entregan los datos es significativo y representativo es poco menos que un dogma de fé y debemos formarnos para interpretar este nuevo mundo que tenemos delante de nosotros.
Tomar decisiones es difícil
Tomar decisiones basadas en datos es muy difícil
Tomar buenas decisiones basadas en datos es dificilísimo.
¿Se pueden tomar malas decisiones basadas con buenos datos? Desde luego
En Leanalytics 005, continuaré con los falsos negativos, el poder estadístico y los errores que solemos cometer los marketers en el campo de la experimentación y la interpretación de resultados.
Fuentes de la 4ª edición:
Frederik Graveter, Larry B Walnau - Statistics for the behavioral economics
Georgi Z. Georgiev - Statistical Methods in Online A/B Testing: Statistics for data-driven business decisions and risk management in e-commerce
Towards Data Science - Tweaking a model for lower False Predictions