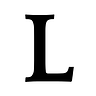

#010 Test AB con Python (II) - Preparar el experimento
#010 Test AB con Python (II) - Preparar el experimento

Segundas partes nunca fueron buenas
Veremos si esta edición se asemeja a El Padrino II y podremos ser ejemplo de una historia que supera a su antecesora o nos convertiremos en Matrix: Reloaded, más conocida como la película que nadie reclamó y que ojalá nunca se hubiera producido.
En esta 10ª edición continúa la trilogía sobre Python y su relación con AB testing. A continuación, nos introduciremos en algunos aspectos clave que debemos conocer antes de experimentar.
Si no estás familiarizado con Python o ningún otro lenguaje, te recomiendo que eches un vistazo a la primera parte de esta trilogía, en la que enseño los más básicos de Python.
Ahora sí, empieza:
Test AB con Python (II): Preparar el experimento

Los puntos que se tratan en esta edición:
Introducción
Nivel de significancia
Potencia estadística
MDE
Randomization unit & SRM
Sample size calculation con Python
Experiment duration con Python
Avance: Cálculo de SRM con Python
Antes de empezar
Se puede encontrar mucha información relacionada con AB testing y Python, sin embargo, Leanalytics se centra —especialmente en esta trilogía— en Online Controlled Experiments, es decir, en experimentos dentro de un sitio web o aplicación. Es importante señalar esta cuestión puesto que los AB tests se aplican a menudo en otros campos como, por ejemplo, medicina o biología.
Uno de los motivos principales por los que se hace esta distinción es porque en un test AB en la mayoría de las disciplinas puedes disponer de un gran control sobre la condición de los individuos del grupo de control y de la variante, pero en Online Controlled Experiments muy pocas veces tendrás el mismo control.
En Online Controlled Experiments los individuos no son personas únicas que consumen en tu sitio web. La métrica usuarios no es una métrica que indique el número de personas que entran en tu sitio web. Las métricas asociadas a usuarios son en muchas ocasiones fruto de la inferencia de un algoritmo cuyo output es que una serie de cookies determinadas —que recordemos, funcionan a nivel de navegador, nunca de dispositivo— son un único usuario.
Como todo modelo de aprendizaje automático tiene un error rate determinado —en el caso de GA4 un 2%—, estamos trabajando con la asunción de que un usuario es una persona determinada, lo cual es tecnológicamente falso. En este hilo de Twitter explico cómo funciona el recuento de usuarios en GA4 con el algoritmo HyperLogLog++ y las consecuencias que esto genera en AB testing.
La estadística en una población volátil
En un mundo en el que no puedes de forma 100% veraz asegurar que estás separando personas entre grupo de control y variante y en el que, además, la población de tu sitio web cambia cada día en función de factores coyunturales como updates de Google, modificaciones en las estrategias de PPC de tus competidores o de tu empresa, aparición de nuevas plataformas e incluso cookies, parecería que la estadística purista no tiene cabida en Online Controlled Experiments.
Para los que no conozcáis a Picanumeros —que, querido lector/a, te recomiendo seguir YA—, es profesor de estadística de la Universidad de Granada y es uno de los más prolíficos creadores de contenido sobre estadística en Twitter. Le pregunté hace varias semanas sobre este asunto y esto fue lo que me contestó:

Lo que debemos extraer de esto que apunta Picanumeros (¡Mil gracias, amigo!) es que ante un mundo tan caótico como el online hay que aportar fuentes externas que ayuden a dar color a tu diagnóstico, especialmente si haces CRO y experimentación online. Es un tema que ya se trató de forma marginal en esta edición de Leanalytics.
Es decir, no podemos ser especialmente puristas con la estadística, lo cual no significa que haya que repudiarla. Es fundamental conocer estadística básica para hacer CRO, pero también es necesario saber que los individuos con los que estamos trabajando tienen asociadas unas características muy, muy específicas.
Ahora sí, AB Testing con Python
Significance Level
Antes de iniciar experimentos debemos tener en cuenta una serie de cosas muy relacionadas con estadística. Una de ellas es el nivel de significancia, la cual podemos definir así:
The significance level is the measure of the strength of the evidence that must be present in your sample before you reject the null hypothesis and conclude that the effect is statistically significant. The significance level is also known as alpha.
Es decir, decimos que el resultado de un experimento ha sido estadísticamente significativo cuando es poco probable —que no imposible— que haya sido debido al azar.
Esto es importante debido a que no deseamos que nuestros experimentos —que apenas tendrán unas semanas de duración— arrojen resultados que no podemos trasladar al resto de los usuarios futuros de la web.
Sobre falsos positivos y falsos negativos, puedes leer Leanalytics 004 y Leanalytics 005 respectivamente, sin embargo, quiero apuntar a la idea de que debemos ser muy cuidadosos con el Type I Error (Falso positivo) y significance level. Si tu nivel de significancia lo ubicas al 0,05 tu Type I Error será también del 0,05.
En la práctica, cuando haces experimentos online puedes modificar tu alpha (significance level) en función de aquello con lo que quieres experimentar. Como bien sabes, hay entornos más sensibles que otros a nivel comercial o incluso a nivel de desarrollo y es valorable modificar el nivel de significancia si lo consideramos adecuado.
Sin embargo, hay que hacerlo en función del contexto y la importancia real y ponderada de la situación, puesto que en la práctica es muy goloso que tanto clientes como colaboradores del mismo consideren que todas las áreas —o aquellas en las que ellos tienen influencia— son las más críticas del negocio. No todo merece un nivel de significancia máximo.
Sin ningún tipo de duda, esta decisión la debe tomar el CRO y habitualmente siempre se trabajará con 0.05 para simplificar los procesos de experimentación e interpretación de los resultados. Aún así, si quieres un rango, este puede servirte:

Statistical Power
Este es un concepto que va fuertemente ligado con los experimentos online y también con los Type II Error —también conocidos como falsos negativos—. Aquí una definición:
The Statistical Power is the probability of rejecting the null hypothesis given that the effect exists, or that the alternative hypothesis is true.
Si observas la gráfica de debajo, como hemos ubicado alpha en 0.05 y la p-valor es inferior a alpha (0.03), podemos rechazar la hipótesis nula. Sin embargo, la potencia estadística tiene una gran importancia también en la preparación de un experimento.

La potencia estadística representa la probabilidad de detectar un efecto en el total de una población cuando éste es real. Como puedes ver en la imagen inferior tiene una relación direccta con los Type II Error. Imagina que un test AB determina que no hay un efecto superior de la variante con respecto al grupo de control y realmente sí hay un efecto: Se trataría de un falso negativo.

Statistical Power y Type II Error -es decir, los falsos negativos- son complementarios. Si estimas que la potencia estadística es de 0.80, significa que tu Type II Error Rate es del 0.20.
Por convención, la potencia estadística se ubica a menudo en 0.80, pero al igual que con el nivel de significancia debemos entender que va a depender del contexto: El contexto determina en qué punto deberías ubicar tu statistical power.
Sin embargo, si deseas un rango aproximado, en entornos en los que tenemos poco tiempo —por una promoción limitada en la que no ha habido tiempo para maniobrar debidamente, por ejemplo—, ubicar en 0.70 puede ser una opción y, si queremos ser muy cuidadosos porque va a tocar temas sensibles —habitualmente con Hippos—, un 0.90.

Statistical Power y Significance Level juegan un papel complementario en la interpretación de los resultados y en la preparación de un experimento, puesto que la potencia estadística nos permite entender en qué medida se ha detectado un efecto o no por su relación con los falsos negativos.
Minimum Detectable Effect (MDE)
¿Qué es exactamente MDE?
It’s the minimum effect size required to achieve statistical significance. MDE often corresponds to practical significance.
Es decir, es el efecto mínimo que necesitamos percibir en un experimento para considerar que realmente existe una significancia estadística. Este valor debería estimarse antes de realizar cualquier experimento online y existen varias maneras de calcularse (D de Cohen, diferencia relativa, absoluta, entre otros).
Si el efecto observado —es decir, el resultado del experimento— es:
Menor a MDE, entonces no existe significancia estadística ni significancia práctica.
Mayor a MDE, entonces sí existe significancia práctica, pero no se garantiza que exista significancia estadística.
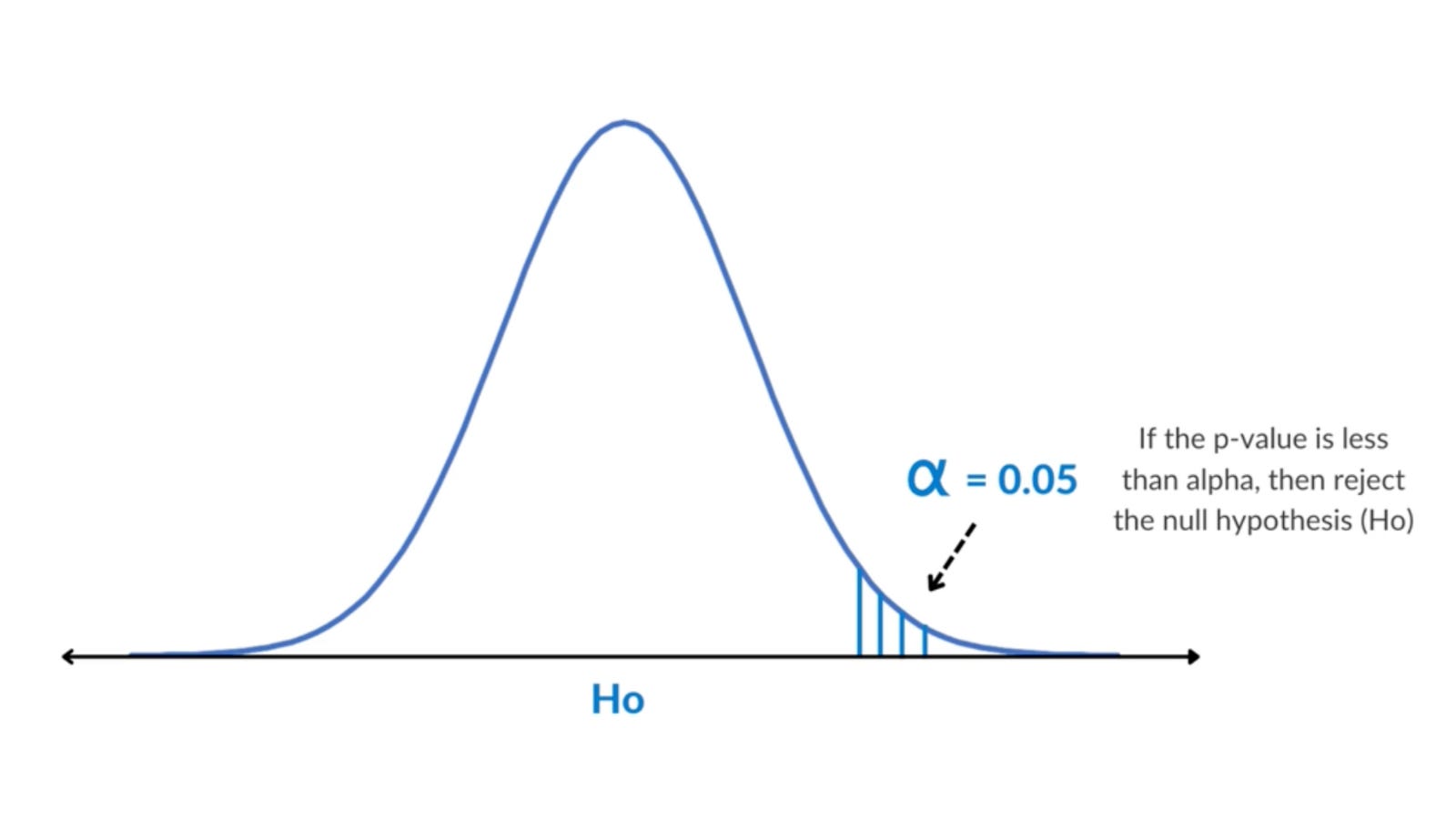
Como ratio aproximado, podríamos plantearnos un MDE del 1% si estamos trabajando con un portal especialmente grande, como Facebook, Instagram o Netflix, minetras que para negocios más modestos, deberíamos aumentar el MDE.
Existen calculadoras que ayudan a evaluar algunos de estos parámetros que se están enseñando en esta edición y que probablemente conozcas, como la calculadora de Optimizely, Statsig o CXL.
Randomization Unit & Sample Ratio Mismatch
Randomization unit is an entity that is randomly assigned to a group in an experiment
Es decir, si el total de tu población está basado en diez usuarios y realizas un AB test, cinco usuarios se dirigirán a un lado y otros cinco a otro. Randomization Unit es el quién o el qué que se agrupa en el grupo de control o la variante.
Cuando diseñamos un experimento es importante evaluar previamente debido a que puede llegar a haber discrepancias en la distribución de los usuarios entre grupo de control y variante. Esto puede provocar que establecer causalidad sea un auténtico quebradero de cabeza.
Aquí entra Sample Ratio Mismatch —también conocido como SRM—, es decir, la desviación que puede llegar a haber entre el grupo de control y la variante, lo que afecta a la capacidad que tenemos de hacer inferencias con los resultados de nuestros experimentos.
Hay muchas herramientas para calcular si tu experimento ha sufrido de SRM. Una que recomiendo por su sencillez es la de Lukas Vermeer: SRM checker, aunque cada vez más herramientas de AB testing tienen SRM checker incorporado por defecto. Más adealante, después de sample size calculation, mostraremos cómo calcularlo con Python.
Sin embargo, con Python, sería algo tal que así. Te recuerdo que en la edición 009 de Leanalytics se hizo una introducción a Python para seguir el código:
Sample Size: Cálculo con Python
Conectado a los usuarios está el cálculo de la muestra. Para ello debemos tener en cuenta los factores previamente explicados: MDE, Power y significance level. El motivo por el que puede ser francamente sano calcular antes el tamaño de la muestra es que nos permite no cometer errores ni caer en sesgos de confirmación como muy bien se explica en este blog de Airbnb sobre errores en experimentación.
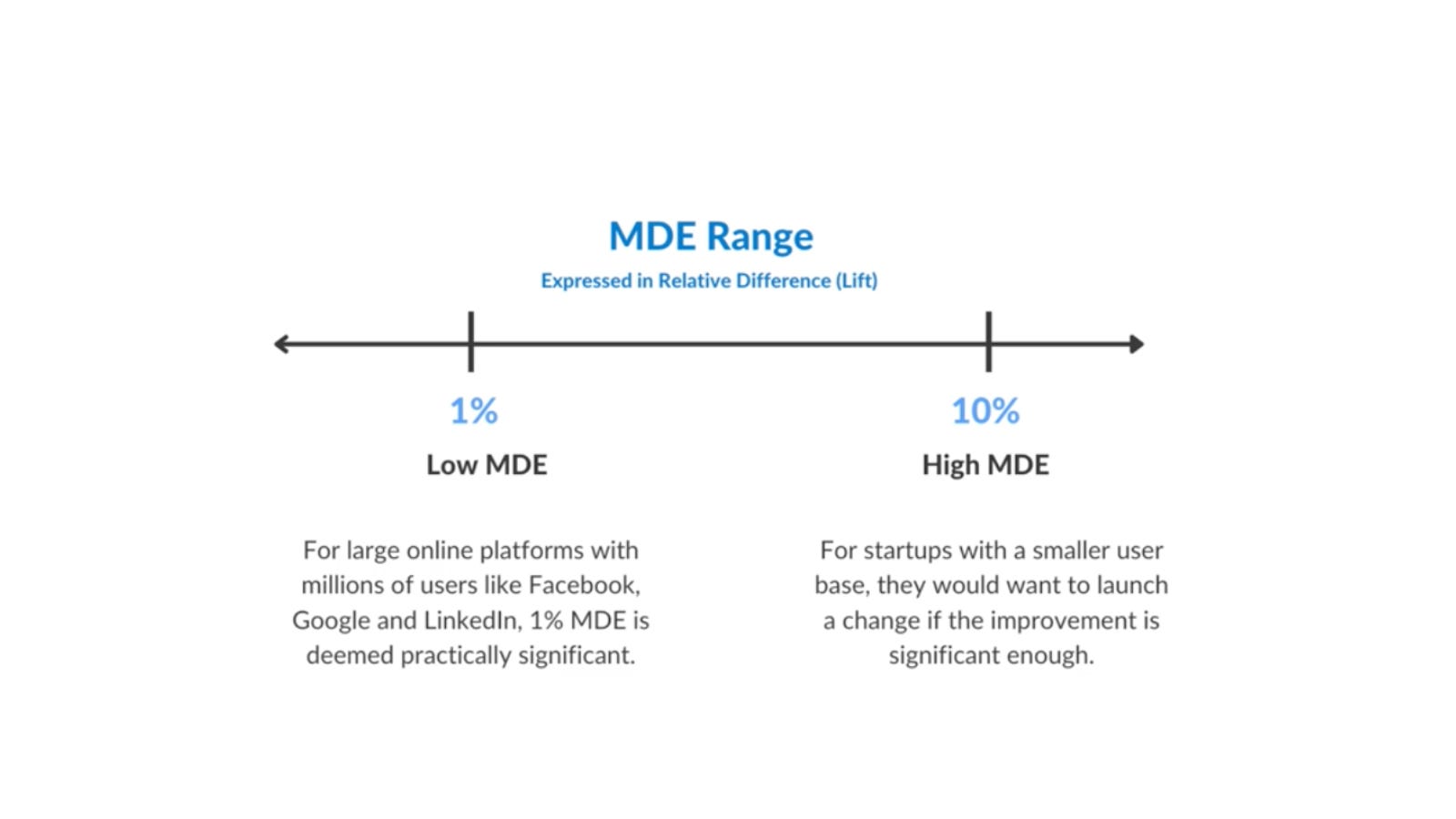
La fórmula del tamaño de una muestra es dependiente de una serie de factores y quizás haré un post algún día centrado únicamente en el cálculo de tamaños mínimos de muestra o de muestreo en general, porque tiene mucho que ver en función de si haces one-tailed o two-tailed experiments:
Para hacer un cálculo sencillo con Python y saber el tamaño de la muestra que necesitamos, podemos usar el siguiente código
from statsmodels.stats.power import TTestIndPower
mde = 0.10 #minimum detectable effect
alpha = 0.05 #significance level, usamos la convención estándar
power = 0.80 #statistical power, usamos la convención estánda
analysis = TTestIndPower()
result = analysis.solve_power(mde, power = power,nobs1= None, ratio = 1.0, alpha = alpha)
print('Sample Size: %.3f' % round(result))¿Qué resultado devuelve? 1.571 usuarios. Es decir, necesitaríamos 1.571 usuarios para cada versión del experimento —en total 3.142 usuarios— si aplicamos esta función. Si pruebas con otros valores verás que el tamaño de la muestra cambia:
Versión con MDE (0,10), alpha (0,05) y power (0.80): 1.571 usuarios por versión

Versión con MDE (0,01), alpha (0,05) y power (0.95): 259.895 usuarios por versión


Como convención:
Si el nivel de significancia desciende, aumenta el tamaño de la muestra
Si la potencia estadística aumenta, aumenta el tamaño de la muestra
Si MDE desciende, aumenta el tamaño de la muestra
Experiment duration
The total duration of days or weeks required to collect the pre-determined sample size in an experiment
Para evaluar la duración que necesitamos de un experimento, necesitamos tener en cuenta:
La naturaleza del experimento (tipo de hipótesis, por ejemplo)
Establecer MDE, Power y alpha
Calcular el tamaño de la muestra
Y una vez tienes estos valores, es tan simple como seguir esta fórmula:

Es decir, trabajaríamos con algo tal que así:
#duration days
sample_size = 14000 #entre los dos grupos
number_unique_visitors_per_day = 10000
perc_daily_traffic_allocated = 0.10
duration = sample_size / (number_unique_visitors_per_day * perc_daily_traffic_allocated)
print('duration days are', round(duration))
Si necesitamos 14.000 usuarios debido al cálculo del tamaño de la muestra —7.000 en el grupo de control y 7.000 en la variante—, tenemos un sitio web con 10.000 visitantes por día y un 10% de usuarios que van a ser afectados por ese experimento —debido a que no todos los usuarios de tu web van a ser afectados por tu experimento—, nos daría que necesitamos que el experimento dure 14 días.
Cálculo con Python de SRM
Aquí va un avance de la edición 011 de Leanalytics. Una pregunta que debes hacerte durante tus proyectos de experimentación online, una vez ya estás capturando resultados, es si tu experimento ha sufrido de SRM. No recomiendo fiarse siempre de herramientas de terceros puesto que dudo que mis incentivos estén en todo momento alineados a los suyos, así que quiero presentarte cómo calcularlo con Python.
Imaginemos un dataset como este, formado por las columnas user_id, version, minutes_play (se testea los minutos de reproducción de un video) y dos columnas que devuelven un booleano que nos permite evaluar en engagement.

Si ejecutamos el siguiente código, verás que la p-valor devuelve 0.010041820594939122. El código muestra los usuarios que ha habido en cada grupo (1600 y 1749) y los usuarios que deberían haber llegado (1675 y 1675)
from scipy.stats import chisquare
chisquare([1600,1749],f_exp = [1675,1675])
Como la p-valor devuelve 0,01 periódico se considera que no hay Sample Ratio Mismatch en este experimento y, por lo tanto, los datos tienen significancia estadística. Esto es muy importante de cara a poder realizar una inferencia correcta entre los usuarios que han habitado nuestro experimento de dos semanas y el resto de usuarios preentes y futuros.
Conclusiones
¿Quién dijo que hacer CRO y experimentación online era fácil?
Deben tenerse en cuenta múltiples factores.
Tecnológicos: Todo lo relacionado con el conteo de usuarios
Estadísticos: Todo lo relacionado con alpha, power, inferencia, muestras, entre otros.
Empresariales: CRO es lectura de contexto e interpretación de la realidad en función de datos
Solamente se ha arañado la superficie ante muchas cuestiones. En siguientes ediciones profundizaré en temas concretos como MDE, SRM o el cálculo de muestras mínimas.
En la última edición veremos qué podemos hacer con los datos que hemos recogido de un test AB y qué clase de decisiones deberíamos tomar en diferentes escenarios.
Solamente hemos arañado la superficie.
CRO no es solo poner dos versiones de una web.
La experimentación online es una de las disciplinas más completas que hay.
CRO es coral.
CRO también se puede hacer con Python.